I en chi i anden-test (læses ”ki i anden test” og skrives også ”\(\chi ^2\)-test’) for uafhængighed undersøger vi om der er uafhængig mellem to data i to forskellige kategorier. Det kunne f.eks. man ville undersøge om der var
uafhængighed mellem landsdel og politisk tilhørsforhold. Altså er folk fra Jylland f.eks. mere tilbøjeligt til at stemme på Venstre end resten af landet? Vi vil vise metoden med udgangspunkt i en undersøgelse af yndlingskage for
elever på Niels Brock. I dette afsnit vil vi primært fokusere på hvordan man gør, og så kommer der forklaringer og detaljer i næste afsnit.
Observerede værdier
Udgangspunktet for at lave en chi i anden-test er nogle observerede værdier. I forhold til vores undersøgelse om yndlingskage ser de således ud:
.
Dreng
Pige
Total
Drømmekage
\(13\)
\(5\)
\(18\)
Chokoladekage
\(14\)
\(11\)
\(25\)
Andet
\(6\)
\(6\)
\(12\)
Total
\(33\)
\(22\)
\(\textbf {55}\)
Tabel 17.1: Observerede værdier
Fastlæggelse af signifikansniveau
Først skal vi fastlægge signifikansniveauet \(\alpha \). Vi lærte også om signifikansniveauer da vi lærte om konfidensintervaller, men vi vil ikke lave nogen forbindelse til den betydning, det havde der. Ligesom ved
konfidensintervaller er det et tal mellem \(0\) og \(1\) typiske opgivet i procent. Har man ikke fået andet at vide, vælge man \(\alpha =5\%\), så det gør vi også her.
Opstilling af hypoteser
Vi skal nu opstille hypoteser. Vi vil gerne finde ud af om der er uafhængighed mellem køn og kage, og det formulerer vi i følgende to hypoteser.
\(H_0\): Der er uafhængighed mellem køn og yndlingskage
\(H_1\): Der er ikke uafhængighed mellem køn og yndlingskage.
Hypotesen \(H_0\) kaldes nulhypotesen og \(H_1\) kaldes den alternative hypotese. I uafhængighedstest har hypoteserne altid denne form bare med andre kategorier end køn og yndlingskage.
Beregning af forventede værdier
På baggrund af \(H_0\) opstiller vi nu de forventede værdier. Dvs. det ville forvente at observere, hvis \(H_0\) var sand. Vi bruger følgende formel:
Vi kan f.eks. beregne det forventede antal drenge, som bedst kan lide chokoladekage. Vi finder først det felt med drenge og chokoladekage (markeret med gult). Herfra aflæser vi rækkesum (grøn), søjlesum (blå) og totalsum (rød):
Som tommelfingerregel skal der være minimum \(5\) i hver af de forventede værdier. Vi har en forventet værdi på \(4{,}8\), så det er lige i underkanten, men da de \(5\) kun er et pejlemærke fortsætter vi alligevel.
Bestemmes af \(\chi ^2\)-teststørrelse
I næste skridt skal vi undersøge hvor stor forskellen er på de forventede og de observerede værdier. Denne forskel udtrykker vi i det vi kalder \(\chi ^2\)-teststørrelsen (eller bare teststørrelsen) som betegnes \(\chi
^2\). Den regnes ud med brøken:
Nu mangler vi bare at finde ud af om vores teststørrelse er så stor, at vi ikke længere tror på \(H_0\). For at kunne svare på det skal vi først bestemme dets som kaldes antallet af frihedsgrader \(f\). Det gør vi med
formlen:
I vores tilfælde bliver antallet af frihedsgrader altså
\[f=(3-1)(2-1)=2.\]
Antallet af frihedsgrader betegnes nogle steder (GeoGebra f.eks.) med \(df\) (står for degrees of freedom).
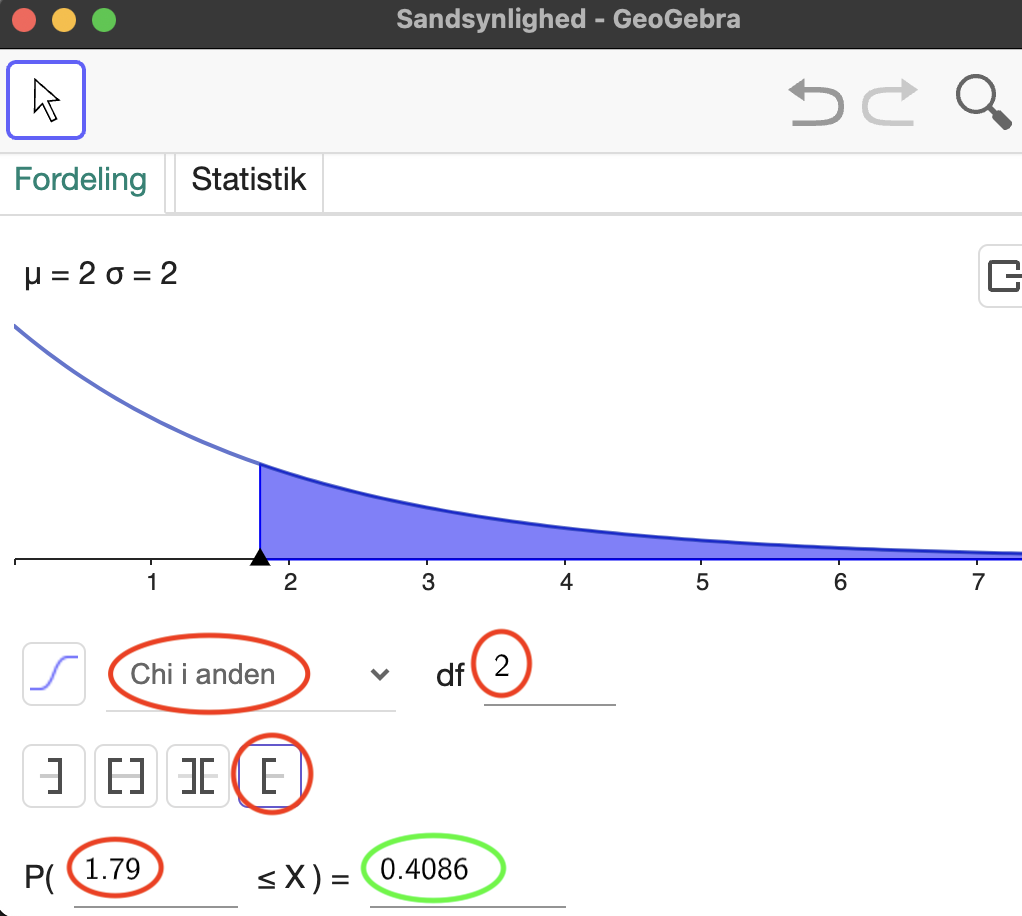
Ud fra antallet af frihedsgrader kan vi omsætte vores teststørrelse til en sandsynlighed i GeoGebras sandsynlighedslommeregner. Til ethvert antal frihedsgrader findes nemlig en sandsynlighedsfordeling, kaldet en \(\chi
^2\)-fordeling, og her skal vi bestemme sandsynligheden
\[P(X\geq \chi ^2)\]
Vi havde \(\chi ^2=1{,}79\), så vi skal altså bestemme \(P(X\geq 1{,}79)\):
Som det ses i screenshottet har vi valgt ”Chi i anden” som fordeling, indtastet frihedsgraderne ud fra ”df” og indtastet teststørrelsen. Vi ser at \(P(X\geq 1{,}79)=0{,}41\). Denne sandsynlighed kaldes \(p\)-værdien. Vi har altså
at
\[p=0{,}41=41\%\]
Løst sagt udtrykker \(p\)-værdien hvor sandsynlige vores observationer er, hvis \(H_0\) er rigtig.
Konklusion
Vi skal nu sammenligne \(p\)-værdien med signifikansniveauet \(\alpha \). Der er to scenarier:
.
Hvis \(p \leq \alpha \)
Vi forkaster \(H_0\). Dette betyder, at der er tilpas stor forskel på de observerede og forventede værdier til, at vi ikke længere kan tro på \(H_0\). Det får os til at tro mest på \(H_1\).
Hvis \(p > \alpha \)
Vi forkaster ikke \(H_0\). Dette betyder, at forskellen mellem observerede og forventede værdier, ikke er tilstrækkelig stor til at afvise \(H_0\). Dette opfatter vi som en bekræftelse af \(H_0\).
I vores tilfælde er \(p=0{,}41=41\%\) og \(\alpha =5\%\) så \(p>\alpha \), og vi kan dermed ikke forkaste \(H_0\). Da \(H_0\) var uafhængighed mellem køn og yndlingskage kan vi konkludere:
Vi har undersøgt om der er uafhængighed mellem køn og yndlingskage. På baggrund af de indsamlede data konkluderer vi, at det godt kan være tilfældet.
Havde \(p < \alpha \) ville konklusionen have været, at der var afhængighed (dvs. sammenhæng) mellem køn og yndlingskage.
Det er vigtigt at påpege, at vi aldrig beviser \(H_0\) eller \(H_1\). Det er mere et spørgsmål om, hvilken en vi tror på.
Øvelse 17.1.1
En gruppe elever lavede i 2014 en undersøgelse i på skolen, hvor de spurgte til om man var til Carlsberg eller Turborg. Resultatet ses her:
.
Kvinde
Mand
Carlsberg
\(7\)
\(7\)
Tuborg
\(7\)
\(8\)
Du skal nu lave en \(\chi ^2\)-test hvor I undersøger, med et \(5\%\) signifikansniveau, om der er sammenhæng mellem køn og yndlingsøl. Du skal altså:
a) Opstille nulhypotesen og den alternative hypotese.
b) Beregne de forventede værdier.
c) Afgøre om vi har nok data til at gennemføre en \(\chi ^2\)-test.
d) Bestemme teststørrelsen.
e) Bestemme antallet af frihedsgrader.
f) Bestemme \(p\)-værdien.
g) Afgøre om vi skal forkaste nulhypotesen.
h) Afgør om der er sammenhæng mellem køn og yndlingsøl.
i) Når du kigger på de observerede hyppigheder er du så overrasket over testens resultat?
Løsning 17.1.1
a) \(H_0\): Der er uafhængighed mellem køn og yndlingsøl.
\(H_1\): Der ikke uafhængighed mellem køn og yndlingsøl.
b)
.
Kvinde
Mand
Carlsberg
\(6{,}7586\)
\(7{,}2414\)
Tuborg
\(7{,}2414\)
\(7{,}7586\)
c) Der er mere end \(5\) i hver af de forventede værdier så det kan vi godt (selvom det ikke er ideelt med så få data)
d) \(\chi ^2=0{,}0322\)
e) Der er 1 frihedsgrad.
f) \(p=0{,}8575\).
g) Vi forkaster ikke.
h) Vi kan ikke påvise nogen sammenhæng mellem køn og yndlingsøl.
i) Det er ingen overraskelse. De observerede hyppigheder kunne ikke være mere lige fordelt!
Ekstra
Man kan skrive (formlerne for) de forskellige størrelser mere præcist, hvis man ikke er bange for indeks og summationstegn.
Generelt ser en tabel over observerede værdier sådan her ud:
.
Søjle 1
Søjle 2
…
sum
Række 1
\(O_{11}\)
\(O_{12}\)
…
\(O_{1\bullet }\)
Række 2
\(O_{21}\)
\(O_{22}\)
\(O_{2\bullet }\)
⋮
⋮
⋮
⋮
sum
\(O_{\bullet 1}\)
\(O_{\bullet 2}\)
…
\(n\)
Vi betegner rækkenumre med \(i\) og søjlenumrene med \(j\), og har vi en observeret værdi i den \(i\)’te række og \(j\)’te søjle, betegner vi den med \(O_{ij}\).
Den \(i\)’te rækkesum kan skrives med formlen:
\[O_{ i \bullet } = \sum _{j} O_{ij}\]
Her betyder \(\sum _{j}\) at vi skal have et led for hver værdi af \(j\), som er de mulige søjlenumre.
Vi kan tilsvarende skrive den \(j\)’te søjlesum med formlen:
\[O_{\bullet j} = \sum _{i} O_{ij}\]
Lægger vi alle de observerede værdier sammen, får vi selvfølgelig stikprøvestørrelsen \(n\):
\[n=\sum _{ij} O_{ij}\]
Her betyder \(\sum _{ij}\) at vi skal have et led for hver mulig kombination af \(i\) og \(j\), dvs. et led for hver observeret værdi.
De forventede værdier for række \(i\) og søjle \(j\) betegnes med \(E_{ij}\) og dens formlen kan selvfølgelig opskrives som: