16.3 Forklaringer og detaljer for chi i anden-test
I dette afsnit vil vi ser nærmere på de enkelte dele i en \(\chi ^2\)-test.
Hypoteser
I almindelig sprogbrug er en en hypotese noget man tror er rigtigt og prøver at bevise. Sådan er det ikke helt i en \(\chi ^2\)-test. Her er nulhypotesen en påstand, man laver sine beregninger ud fra.
GOF-test:
Her er nulhypotesen altid, at vores observationer følger en bestemt fordeling.
Uafhængighedstest:
Her er nulhypotesen altid uafhængighed mellem de to kategorier (f.eks. køn og yndlingskage).
Den alternative hypotese er altid ”følger ikke fordelingen” for GOF-test og ”ikke uafhængighed” for uafhængighedstest.
Forventede værdier
For en GOF-test giver det lidt sig selv, hvad de forventede værdier er. Hvis vi forventer, at der er \(20\%\) sandsynlighed for at en kunde vælger Faxe Kondi, og vi spørger 50 kunder om, hvad de vil vælge, så vil vi selvfølgelig
forvente, at \(20\%\) af de \(50\) kunder vil sige ”Faxe Kondi”.
For en uafhængighedstest regnes de forventede værdier med formlen.
Vi vil forklare formlen med udgangspunkt i drenge, som foretrækker chokoladekage. Vi har tabellen med observerede værdier.
.
Dreng
Pige
Total
Drømmekage
\(13\)
\(5\)
\(18\)
Chokoladekage
\(14\)
\(11\)
\(25\)
Andet
\(6\)
\(6\)
\(12\)
Total
\(33\)
\(22\)
\(\textbf {55}\)
Andelen af personer i undersøgelsen, som fortrækker chokoladekage, er givet ved \(\frac {25}{55}\). Hvis \(H_0\) er rigtig (uafhængighed mellem køn og kage), må andelen af drenge som fortrækker chokoladekage være den
samme som andelen for de to køn tilsammen. Dvs. andelen af drenge som fortrækker chokoladekage må også være \(\frac {25}{55}\). Da der er \(33\) drenge, vil vi forvente, at antallet af drenge i stikprøven, som fortrækker
chokoladekage, er:
a) Gentag ovenstående argumentation, men for piger som foretrækker drømmekage i stedet:
16.3.1
a) Andelen af personer i undersøgelsen, som fortrækker drømmekage er givet ved \(\frac {18}{55}\). Hvis \(H_0\) er rigtig (uafhængighed mellem køn
og kage), må andelen af piger, som fortrækker drømmekage være den samme som andelen for de to køn tilsammen. Dvs. andelen af piger, som fortrækker drømmekage, må også være \(\frac {18}{55}\). Da det er \(22\) piger vil
vi forvente at antallet af piger i stikprøven, som fortrækker drømmekage, er:
Årsagen til, at vi kræver minimum \(5\) i hver af de forventede værdier, har noget at gøre med de \(\chi ^2\)-fordelinger, vi bruger til at finde \(p\)-værdien. Teststørrelsen følger kun tilnærmelsesvis disse fordelinger, og er
stikprøven lille, bliver \(p\)-værdien upræcis.
bliver stor, når forskellen mellem de observerede og de forventede værdier er stor. Nævneren afhænger ikke af denne forskel. Så en stor forskel på de observerede og de forventede værdier vil give en stor værdi af brøken. Da
teststørrelsen består af summen af alle bidragene, vil en stor forskel på observerede og forventede værdier give en stor teststørrelse.
Signifikansniveau og \(p\)-værdier
Når vi laver en chi i anden-test, undersøger vi, om de observerede værdier svarer til de forventede værdier. Men fordi de observerede værdier kun udgør en stikprøve, kan vi ikke regne med, at de svarer fuldstændig til de forventede.
Derfor kan man ikke forkaste \(H_0\), bare fordi de observerede værdier ikke svarer helt til de forventede. Det er kun, når det ser meget ”skævt ud”, at vi forkaster \(H_0\). Vi bruger \(p\)-værdien til at fastlægge, hvor skæve vores
observerede værdier er i forhold til de forventede. Denne værdi findes i GeoGebra ved at bestemme:
\[P(X \geq Q)\]
Vi skal nu se, hvad den sandsynlighed udtrykker helt præcis. Lad os sige, at vi tester en sand \(H_0\) flere gange. Dvs. vi laver flere stikprøver. Hver gang vil vi få en lidt forskellig teststørrelse, da vi må forvente lidt variation, alt
efter hvad stikprøven lige består af. Når vi åbner \(\chi ^2\)-fordelingen i GeoGebra, ser vi den fordeling, der beskriver sandsynligheden for at få forskellige værdier for teststørrelsen. Sandsynligheden \(P(X \geq Q)\) er altså
sandsynligheden for at få en teststørrelse der er større end eller lige så stor som den vi har, hvis vi gik ud og lavede den samme \(\chi ^2\)-test, men på en ny stikprøve. Så vi kan altså beskrive \(p\)-værdien på følgende måde:
Tallet \(p\)-værdien er sandsynligheden for at få en teststørrelse, som er ligeså stor eller endnu større end den vi har fået, under forudsætning af at \(H_0\) er sand.
Hvis vi får en \(p\)-værdi på f.eks. \(2\%\), betyder det altså, at hvis \(H_0\) er sand, er det kun i \(2\%\) af stikprøverne, at man vil få ligeså skæve observerede værdier (dvs. med lige stor forskel fra de forventede værdier) som
dem vi har fået. Men, hvis det kun er i \(2\%\) af tilfældene, man vil få ligeså skæve observerede værdier, som dem vi har fået, kan vi så stadig tro på \(H_0\)? Hvor skal vi sætte grænsen for, hvor usandsynlige vores observerede
værdier må være? Den grænse fastlægges med signifikansniveauet, som normalt vælges til \(5\%\).
Antallet af frihedsgrader
Antallet af frihedsgrader er det antal af observerede værdier, vi skal kende, for at kunne regne resten af de observerede værdier ud, når vi kender totalerne.
Eksempel 16.3.1 Betragt tabellen fra GOF-testen med sodavand:
.
Coca Cola
Faxe Kondi
Fanta
21
12
17
Hvis vi ved, at vi har har spurgt \(50\) kunder, skal vi kende to af værdierne i tabellen for at kunne regne resten ud. Altså hvis vi f.eks. ikke vidste, at der var \(17\) der svarede Fanta, kan man regne sig frem til de \(17\) ved at
sige:
\[50-21-12=17\]
Ud fra ovenstående eksempel er det klart, at vi kan genskabe tabellen, hvis vi kun mangler de observerede værdier fra én af kategorierne. Mangler vi observerede værdier fra mere end én kategori, så bliver det en umulig opgave.
Derfor er antallet af frihedsgrader:
\[df=\text {antal af kategorier} - 1\]
For uafhængighedstesten er det samme princip, men lidt mere kompliceret. Lad os se på yndlingskageeksemplet:
.
Dreng
Pige
Total
Drømmekage
\(13\)
\(18\)
Chokoladekage
\(14\)
\(25\)
Andet
\(12\)
Total
\(33\)
\(22\)
\(\textbf {55}\)
Det ses at jeg har fjernet en hel række og en hel søjle. Men jeg kan stadig genskabe data. Lad os genskabe antallet af piger, der valgte drømmekage. Vi ved at der var 18 personer som valgte drømmekage og 13 af dem var drenge, så
antallet af piger som valgte drømmekage må være:
\[18-13=5\]
Øvelse 16.3.3
Beregn ud fra ovenstående tabel:
a) Antallet af piger som valgte chokoladekage.
b) Antallet af drenge som valgte andet.
16.3.3
a) \(11\)
b) \(6\)
Det er klart, at når vi har slettet en række og en søjle, så kan vi ikke slette mere uden at miste muligheden for at genskabe de slettede værdier. Antallet af frihedsgrader må derfor (se øvelsen lige under) være givet ved:
a) Det er klart. Antallet af rækker, der er tilbage er nemlig:
\[\textrm {antal rækker} -1\]
Antallet af søjler, der er tilbage er
\[\textrm {antal søjler} - 1\]
Når man ganger de to, får man selvfølgelig antallet af felter der er tilbage (felter med observationer kun — ikke medregnet totalerne)
Øvelse 16.3.5()
Som tidligere forklaret, er antallet af frihedsgrader det antal af observerede værdier, vi skal kende, for at kunne regne resten af de observerede værdier ud, når vi kender det totalerne.
a) Hvorfor tror du, det hedder frihedsgrader?
16.3.5
a) Fjerner vi alle de felter vi kan før vi ikke længere kan genskabe tabellen er antallet af felter tilbage det samme som antallet af frihedsgrader. Disse
værdier er ikke fastlagt ud fra de andre og er i den forstand ”frie”.
Kritiske værdier
I en \(\chi ^2\)-test regner vi teststørrelsen \(Q\) som et mål for afvigelsen mellem det forventede og det observerede. Er \(Q\) for stor forkaster vi. Indtil videre har vi afgjort dette ved at sammenligne \(p\)-værdien med
signifikansniveauet. Dette kræver dog et værktøj til at finde \(p\)-værdien. Har man ikke sådan et værktøj, er der en anden mulighed, nemlig at lave en tabel som viser hvor stor \(Q\) må være, før vi forkaster. Disse værdier kaldes
kritiske værdier. Et udsnit af en sådan tabel ses nedenunder:
Tabel 16.6: Tabel med kritiske værdier. I første søjle har vi frihedsgraderne og de tre næste søjler viser de kritiske værdier for hhv. \(\alpha =10\%\), \(\alpha =5\%\) og \(\alpha =1\%\).
Vi betegner den kritiske værdi med \(KV\). I tabellen kan vi f.eks. se, at \(KV=3{,}84\), når \(\alpha =5\%\) og \(df=1\). Har vi bestemt teststørrelsen, kan vi aflæse den kritiske værdi i tabellen og sammenligne med teststørrelsen:
.
Situation
Handling
\(Q\geq KV\)
Vi forkaster \(H_0\). Dette betyder, at der er tilpas stor forskel på de observerede og forventede værdier til, at vi ikke længere kan tro på \(H_0\). Det får os til at tro på \(H_1\).
\(Q< KV\)
Vi forkaster ikke \(H_0\). Dette betyder, at forskellen mellem observerede og forventede værdier ikke er tilstrækkelig stor til at afvise \(H_0\). Dette opfatter vi som en bekræftelse af \(H_0\).
Eksempel 16.3.2 Antag, at vi er ved at lave en \(\chi ^2\)-test med et signifikansniveau på \(1\%\), med 2 frihedsgrader og vi har fået \(Q=5{,}13\). Vi finder nu den kritiske værdi svarende til \(\alpha
=1\%\). Vi kigger i den sidste søjle og ser at \(KV=9{,}21\). For at finde ud af om vi skal forkaste, skal vi sammenligne med \(Q=5{,}13\) med \(KV=9{,}21\). Da \(Q\) er mindre end \(KV\), vil vi ikke forkaste \(H_0\).
Læg mærke til at det fungerer omvendt sammenlignet med \(p\)-værdien. Vi forkaster, når \(p\)-værdien er under signifikansniveauet, mens vi forkaster, når teststørrelsen er over den kritiske værdi.
Øvelse 16.3.6
Antag, at vi er ved at lave en \(\chi ^2\)-test med et signifikansniveau på \(5\%\) med 3 frihedsgrader og vi har fået \(Q=8\).
a) Afgør om vi skal forkaste \(H_0.\)
16.3.6
a) Vi forkaster da \(8>7{,}81\).
Vi skal nu se, hvor de kritiske værdier i tabellen kommer fra. Fra tidligere ved vi, at vi forkaster, hvis \(p\)-værdien er mindre end eller lig med signifikansniveauet. Derfor kan vi finde de kritiske værdier ved at finde den
\(Q\)-værdi, som giver en \(p\)-værdi, der er lig med signifikansniveauet, da den vil markere grænsen, hvor vi forkaster.
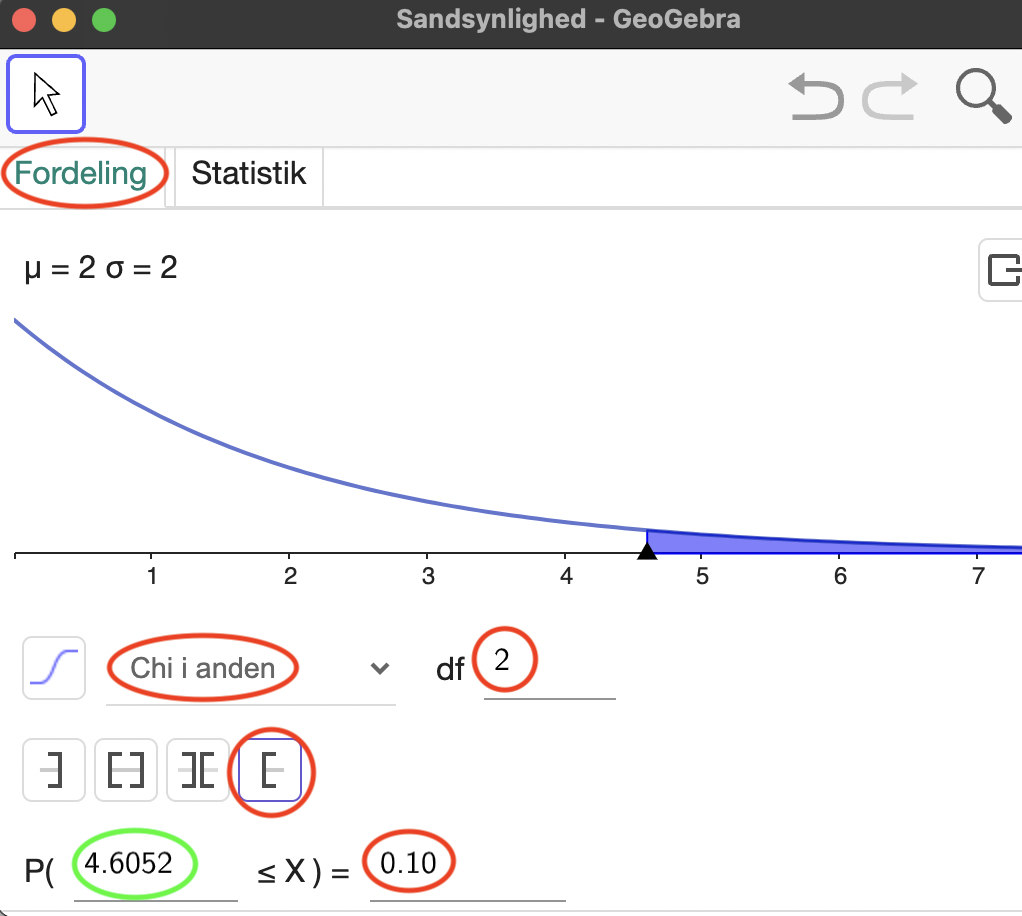
Eksempel 16.3.3 Vi vil nu eftervise at det er rigtigt, at hvis signifikansniveauet er på \(10\%\) i en test med \(2\) frihedsgrader, så vil vi have en kritisk værdi på \(4{,}61\). Vi åbner
sandsynlighedslommeregneren i GeoGebra, finder \(\chi ^2\)-fordelingen og indskriver antallet af frihedsgrader og signifikansniveauet, der hvor vi normalt aflæser \(p\)-værdien:
Vi kan se, at den \(Q\)-værdi som svare til et signifikansniveau på \(10\%\) er \(4{,}61\). Alså er \(KV=4{,}61\) når \(\alpha =10\%\) og \(df=2\)
Øvelse 16.3.7
a) Bestem den kritiske værdi for en \(\chi ^2\)-test med \(df=6\) og et signifikansniveau på \(5\%\).
16.3.7
a) \(KV=12{,}59\)
Bidrag til teststørrelsen
I en \(\chi ^2\)-test for uafhængighed undersøger vi, om stikprøven er i overensstemmelse med \(H_0\). Men det er også interessant hvordan stikprøven afviger fra \(H_0\). Lad os sige, at vi tester om der er
uafhængighed mellem køn og politisk overbevisning (stemmer rødt eller blåt). Her er det ikke kun interessant om der en forskel, men også i hvilken retning den er. Har kvinder en højere tilbøjelighed til at stemme rødt end mænd?
Eller er det mon omvendt?
Vi vender tilbage til undersøgelsen med sammenhæng mellem køn og kage. Vi husker at bidragene til teststørrelsen var bestemt ved:
Vi ser nu at de største bidrag kommer fra drømmekage. Specielt piger og drømmekage. Vi har observeret at der er 5 piger som fortrækker drømmekage, men da vi regnede de forventede værdier fandt vi at resultatet var \(7{,}2\).
Det er jo ikke en særlig stor forskel, og vi endte jo også at beholde \(H_0\). Så vi kan sige, at den største afvigelse fra \(H_0\) var pigernes manglende lyst til at spise drømmekage, men at denne forskel ikke var signifikant. I
forbindelse med statistiske test betyder ”ikke signifikant”, at vi ikke med rimelig sikkerhed kan afvise at resultatet skyldes en tilfældighed. Tilsvarende er et resultat ”signifikant”, hvis vi er rimelige sikre på at resultatet rent faktisk
er gældende.
Øvelse 16.3.8
I GOF-testen med sodavandskunder havde vi disse observerede værdier:
.
Coca Cola
Faxe Kondi
Fanta
21
12
17
og vi havde disse forventede værdier:
.
Coca Cola
Faxe Kondi
Fanta
\(25\)
\(15\)
\(10\)
a) Opstil en tabel med bidragene til teststørrelsen.
b) Hvor er den største bidrag? og hvad betyder det?
16.3.8
a)
.
Coca Cola
Faxe Kondi
Fanta
\(0{,}64\)
\(0{,}6\)
\(4{,}9\)
b) Det klart største bidrag er ved Fanta. Det betyder, at det er er ved Fanta, at efterspørgslen afveg mest fra det vi forventede.
Øvelse 16.3.9
Antag at du producerer terninger og at du producerer 4-siddet terninger. Du afprøver nu en terning for at teste om den er fair (dvs. der er lige stor sandsynlighed for alle resultater). Du får
.
1’ere
2’ere
3’ere
4’ere
\(18\)
\(15\)
\(25\)
\(22\)
Du skal nu lave en \(\chi ^2\)-test hvor I undersøger, med et \(5\%\) signifikansniveau, om din terning er fair. Du skal gøre det uden at bruge GeoGebra. Lommeregner/Excel er ok.
a) Opstil nulhypotesen og den alternative hypotese.
b) Beregn de forventede værdier.
c) Afgør om vi har nok data til at gennemføre en GOF-test.
d) Bestem teststørrelsen.
e) Bestem antallet af frihedsgrader.
f) Bestem den kritiske værdi
g) Afgør om vi skal forkaste nulhypotesen.
h) Er terningen fair?
16.3.9
a) \(H_0\): Kastet følger en uniform fordeling
\(H_1\): Kastet følger ikke en uniform fordeling
b)
.
1’ere
2’ere
3’ere
4’ere
\(20\)
\(20\)
\(20\)
\(20\)
c) Der er mere end \(5\) i hver af de forventede værdier så det kan vi godt.
d) \(Q=2{,}9\)
e) Der er 3 frihedsgrader.
f) \(KV=7{,}81\).
g) Vi forkaster ikke, da teststørrelsen er under den kritiske værdi.
h) hmm det er lidt svært at sige. Vores test viser, at vi ikke har grund til at tro, at der er noget galt med terningen, men vi burde nok have slået lidt flere
gange.
Øvelse 16.3.10
En matematiklærer undersøgte i 2022, hvordan det så ud med fritidsaktiviteter på de forskellige årgange på de gymnasiale uddannelser i Danmark. Tre gymnasieklasser (business-science, Niels Brock, HHX), en på hver årgang, blev
stillet spørgsmålet:
Går du til en fritidsaktivitet som f.eks. fodbold, guitar eller porcelænsmaling?
Resultatet var
.
Går til noget
Går ikke til noget
Total
1. år
\(15\)
\(15\)
\(30\)
2. år
\(8\)
\(7\)
\(15\)
3. år
\(4\)
\(12\)
\(16\)
Total
\(27\)
\(34\)
\(\textbf {61}\)
Undersøg med et signifikansniveau på \(5\%\) om der er sammenhæng mellem årgang og tendens til at gå til fritidsaktiviteter. Du skal gøre det uden at anvende GeoGebra (lommeregner/Excel er ok). Hvis der er en
sammenhæng, så undersøg hvordan sammenhængen er. Alstå. du skal lave en \(\chi ^2\)-test hvor du skal:
a) Opstille hypoteser.
b) Regne forventede værdier.
c) Regne teststørrelsen
d) Bestemme antallet af frihedsgrader
e) Afgøre om \(H_0\) skal forkastes ved sammenligning med den kritiske værdi.
f) Analysere bidragene til teststørrelsen i sammenhæng med de observerede og forventede værdier.
g) Skriv en konklusion af din undersøgelse. Hvad har du undersøgt og hvad er du nået frem til. Det skal fylde et par linjer.
16.3.10
a) \(H_0\): Der er uafhængighed mellem årgang tilbøjelighed til at gå til en fritidsaktivitet.
\(H_1\): Der er ikke uafhængighed mellem årgang tilbøjelighed til at gå til en fritidsaktivitet.
b) Forventende værdier:
.
Går til en noget
Går ikke til noget
Total
1. år
\(13{,}28\)
\(16{,}72\)
\(30\)
2. år
\(6{,}64\)
\(8{,}36\)
\(15\)
3. år
\(7{,}08\)
\(8{,}92\)
\(16\)
Total
\(27\)
\(34\)
\(\textbf {61}\)
c) \(Q=3{,}31\)
d) Der er 2 frihedsgrader.
e) Den kritiske værdi er \(5{,}99\) så vi forkaster ikke \(H_0\)
f) Bidragene ser således ud:
.
Går til en noget
Går ikke til noget
1. år
\(0{,}22\)
\(0{,}18\)
2. år
\(0{,}28\)
\(0{,}22\)
3. år
\(1{,}34\)
\(1{,}07\)
Bidragene er klart højest for 3. år. Sammenligner man observerede og forventede værdier, ser ud til at der er færre elever på 3. går til fritidsaktiviteter. Sammenhængen er dog ikke signifikant (som vi så i delspørgsmål e), så det kan
ligeså godt være en tilfældighed.
g) Vi har undersøgt om der er nogen sammenhæng mellem årgang og tendens til at dyrke fritidsaktiviteter. På baggrund af de indsamlede data har vi ikke
kunne konstatere nogen signifikant forskel på de 3 årgange.
Man kunne godt undre sig over resultatet her. Kigger man på de observerede værdier ser det ud til at der er en markant tilbagegang i andelen af elever som dyrker fritidsaktiviteter når de når til 3. år. Hvorfor ender vi så alligevel
med at beholde \(H_0\)? Det skyldes at det er relativt få elever der skaber den tilsyneladende store ændring på 3. år. Vi skal kun flytte 4 (ud af de 61) elever i undersøgelsen og så har vi en ca. 50/50 fordeling på alle tre årgang. Det
kunne jo sagtens være en tilfældighed, at de bare var lidt mere dovne, i den klasse vi har spurgt (sorry 3.s 2022). Det ville være smart at lave en undersøgelse med nogle flere klasser, men det er jeg desværre for doven til.
Øvelse 16.3.11
Tag udgangspunkt i eksemplet med køn og yndlingskage:
.
Dreng
Pige
Total
Drømmekage
\(13\)
\(5\)
\(18\)
Chokoladekage
\(14\)
\(11\)
\(25\)
Andet
\(6\)
\(6\)
\(12\)
Total
\(33\)
\(22\)
\(\textbf {55}\)
a) Man kan bruge undersøgelsen til at teste, om der er lige mange drenge og piger blandt eleverne på Niels Brock. Forklar hvordan.
b) Afgør ud fra undersøgelsen, om der er lige mange piger og drenge på Niels Brock?
16.3.11
a) Man kan lave en GOF-test og afgøre om kønnet følger en uniform fordeling.
b) Når vi tester for uniform fordeling, får vi en \(p\)-værdi på \(13{,}8\%\) og det betyder, at vi ikke kan konstatere nogen skævhed i kønsfordelingen.
Øvelsen her viser igen problemet med at lave \(\chi ^2\)-test på små stikprøver. For der er nok ikke lige mange drenge og piger på Niels Brock. Vores stikprøve er bare ikke stor nok til at afsløre skævheden.
Ekstra
Betegnelse for kritiske værdier
Vi har indtil videre betegnet kritiske værdier med \(KV\). Der findes dog også en anden lidt mere teknisk betegnelse:
\(\begin {array}{| l | l | c | c | c |} \hline \alpha & 10\% & 5\% & 1\% \\ \hline \text {Betegnelse for kritisk værdi} & \chi ^2_{0{,}90} & \chi ^2_{0{,}95} & \chi
^2_{0{,}99} \\ \hline \end {array}\)
Bruger man disse betegnelser kan man opskrive tabel 16.6 således:
Tabel 16.7: Tabel med kritiske værdier. I første søjle har vi frihedsgraderne og de tre næste søjler viser de kritiske værdier for hhv. \(\alpha =10\%\), \(\alpha =5\%\) og \(\alpha =1\%\).
Betegnelserne kommer af, at kritiske værdi er ”fraktiler i \(\chi ^2\)-fordelingen”. Den nærmere forklaring må vente til på A-niveau, da den kræver lidt viden om kontinuerte stokastiske variable, som hører til på A-niveau.
Type 1 og type 2 fejl
Når vi vælger signifikansniveauet, er vi i et dilemma. Vælger vi det meget lavt, så skal der meget til før, at vi forkaster \(H_0\). Så selvom vores observerede værdier er meget skæve i forhold til de forventede, så forkaster vi ikke
\(H_0\). Undlader vi at forkaste en nulhypotese, som rent faktisk er falsk, siges det at være en type 2 fejl.
Vælger vi signifikansniveauet højt, virker det omvendt. Så vil vi have en tendens til at forkaste \(H_0\), selvom de observerede værdier ikke afviger specielt meget fra de forventede. Dvs. vi risikere at forkaste en sand \(H_0\). Dette
kaldes det en type 1 fejl.
Usandsynlige observerede værdier kan fremkomme på to måder. Det kan være fordi \(H_0\) er forkert, eller fordi vi bare har været uheldige med stikprøven. Matematikken kan ikke hjælpe os til at afgøre, hvilken en af situationerne
vi er i. Hvis vi vælger \(\alpha =5\%\), betyder det, at vi forkaster \(H_0\), når de observerede værdier er så skæve, at det kun sker i \(5\%\) af tilfældene, hvor \(H_0\) er sand. Men det må jo medføre at er en \(5\%\) risiko for at
vi forkaster en sand \(H_0\) – altså at lave en type 1 fejl. Så signifikansniveauet er sandsynligheden for at begå en type 1 fejl (når \(H_0\) er sand).
Øvelse 16.3.12
Antag at vi laver en \(\chi ^2\)-test med et signifikansniveau på \(10\%\).
a) Antag at \(H_0\) er sand. Hvad er sandsynligheden for at begå en fejl af type 1?
b) Antag at \(H_0\) er sand. Hvad er sandsynligheden for at begå en fejl af type 2?
c) Antag at \(H_0\) er falsk. Hvad er sandsynligheden for at begå en fejl af type 1?
d) Antag at \(H_0\) er falsk. Hvad er sandsynligheden for at begå en fejl af type 2? Tænk lidt over det og tjek så facit.
16.3.12
a) Den er \(10\%\)
b) Den er \(0\). Man kan ikke begå en type 2 fejl, når \(H_0\) er sand.
c) Den er \(0\). Man kan ikke begå en type 1 fejl, når \(H_0\) er falsk.
d) Det står der ikke noget om i teksten, så det er måske et lidt unfair spørgsmål. Men tænker man sig om, så er det klart, at man ikke kan udtale sig om
denne sandsynlighed. Det kommer jo an på, hvor forkert \(H_0\) er. Tester man f.eks. uafhængighed mellem kromosomsammensætning hos mennesker (’XX’ eller ’XY’) og køn (tildelt ved fødslen må jeg vist hellere sige), så er der
\(0\%\) sandsynlighed for begå en type 2 fejl.